Getting started with Intel x86 SSE SIMD instructions
Solution 1:
First, I don't recommend on using the built-in functions - they are not portable (across compilers of the same arch).
Use intrinsics, GCC does a wonderful job optimizing SSE intrinsics into even more optimized code. You can always have a peek at the assembly and see how to use SSE to it's full potential.
Intrinsics are easy - just like normal function calls:
#include <immintrin.h> // portable to all x86 compilers
int main()
{
__m128 vector1 = _mm_set_ps(4.0, 3.0, 2.0, 1.0); // high element first, opposite of C array order. Use _mm_setr_ps if you want "little endian" element order in the source.
__m128 vector2 = _mm_set_ps(7.0, 8.0, 9.0, 0.0);
__m128 sum = _mm_add_ps(vector1, vector2); // result = vector1 + vector 2
vector1 = _mm_shuffle_ps(vector1, vector1, _MM_SHUFFLE(0,1,2,3));
// vector1 is now (1, 2, 3, 4) (above shuffle reversed it)
return 0;
}
Use _mm_load_ps or _mm_loadu_ps to load data from arrays.
Of course there are way more options, SSE is really powerful and in my opinion relatively easy to learn.
See also https://stackoverflow.com/tags/sse/info for some links to guides.
Solution 2:
Since you asked for resources:
A practical guide to using SSE with C++: Good conceptual overview on how to use SSE effectively, with examples.
MSDN Listing of Compiler Intrinsics: Comprehensive reference for all your intrinsic needs. It's MSDN, but pretty much all the intrinsics listed here are supported by GCC and ICC as well.
Christopher Wright's SSE Page: Quick reference on the meanings of the SSE opcodes. I guess the Intel Manuals can serve the same function, but this is faster.
It's probably best to write most of your code in intrinsics, but do check the objdump of your compiler's output to make sure that it's producing efficient code. SIMD code generation is still a fairly new technology and it's very possible that the compiler might get it wrong in some cases.
Solution 3:
I find Dr. Agner Fog's research & optimization guides very valuable! He also has some libraries & testing tools that I have not tried yet. http://www.agner.org/optimize/
Solution 4:
Step 1: write some assembly manually
I recommend that you first try to write your own assembly manually to see and control exactly what is happening when you start learning.
Then the question becomes how to observe what is happening in the program, and the answers are:
- GDB
- use the C standard library to
printandassertthings
Using the C standard library yourself requires a little bit of work, but nothing much. I have for example done this work nicely for you on Linux in the following files of my test setup:
- lkmc.h
- lkmc.c
- lkmc/x86_64.h
Using those helpers, I then start playing around with the basics, such as:
- load and store data to / from memory into SSE registers
- add integers and floating point numbers of different sizes
- assert that the results are what I expect
addpd.S
#include <lkmc.h>
LKMC_PROLOGUE
.data
.align 16
addps_input0: .float 1.5, 2.5, 3.5, 4.5
addps_input1: .float 5.5, 6.5, 7.5, 8.5
addps_expect: .float 7.0, 9.0, 11.0, 13.0
addpd_input0: .double 1.5, 2.5
addpd_input1: .double 5.5, 6.5
addpd_expect: .double 7.0, 9.0
.bss
.align 16
output: .skip 16
.text
/* 4x 32-bit */
movaps addps_input0, %xmm0
movaps addps_input1, %xmm1
addps %xmm1, %xmm0
movaps %xmm0, output
LKMC_ASSERT_MEMCMP(output, addps_expect, $0x10)
/* 2x 64-bit */
movaps addpd_input0, %xmm0
movaps addpd_input1, %xmm1
addpd %xmm1, %xmm0
movaps %xmm0, output
LKMC_ASSERT_MEMCMP(output, addpd_expect, $0x10)
LKMC_EPILOGUE
GitHub upstream.
paddq.S
#include <lkmc.h>
LKMC_PROLOGUE
.data
.align 16
input0: .long 0xF1F1F1F1, 0xF2F2F2F2, 0xF3F3F3F3, 0xF4F4F4F4
input1: .long 0x12121212, 0x13131313, 0x14141414, 0x15151515
paddb_expect: .long 0x03030303, 0x05050505, 0x07070707, 0x09090909
paddw_expect: .long 0x04030403, 0x06050605, 0x08070807, 0x0A090A09
paddd_expect: .long 0x04040403, 0x06060605, 0x08080807, 0x0A0A0A09
paddq_expect: .long 0x04040403, 0x06060606, 0x08080807, 0x0A0A0A0A
.bss
.align 16
output: .skip 16
.text
movaps input1, %xmm1
/* 16x 8bit */
movaps input0, %xmm0
paddb %xmm1, %xmm0
movaps %xmm0, output
LKMC_ASSERT_MEMCMP(output, paddb_expect, $0x10)
/* 8x 16-bit */
movaps input0, %xmm0
paddw %xmm1, %xmm0
movaps %xmm0, output
LKMC_ASSERT_MEMCMP(output, paddw_expect, $0x10)
/* 4x 32-bit */
movaps input0, %xmm0
paddd %xmm1, %xmm0
movaps %xmm0, output
LKMC_ASSERT_MEMCMP(output, paddd_expect, $0x10)
/* 2x 64-bit */
movaps input0, %xmm0
paddq %xmm1, %xmm0
movaps %xmm0, output
LKMC_ASSERT_MEMCMP(output, paddq_expect, $0x10)
LKMC_EPILOGUE
GitHub upstream.
Step 2: write some intrinsics
For production code however, you will likely want to use the pre-existing intrinsics instead of raw assembly as mentioned at: https://stackoverflow.com/a/1390802/895245
So now I try to convert the previous examples into more or less equivalent C code with intrinsics.
addpq.c
#include <assert.h>
#include <string.h>
#include <x86intrin.h>
float global_input0[] __attribute__((aligned(16))) = {1.5f, 2.5f, 3.5f, 4.5f};
float global_input1[] __attribute__((aligned(16))) = {5.5f, 6.5f, 7.5f, 8.5f};
float global_output[4] __attribute__((aligned(16)));
float global_expected[] __attribute__((aligned(16))) = {7.0f, 9.0f, 11.0f, 13.0f};
int main(void) {
/* 32-bit add (addps). */
{
__m128 input0 = _mm_set_ps(1.5f, 2.5f, 3.5f, 4.5f);
__m128 input1 = _mm_set_ps(5.5f, 6.5f, 7.5f, 8.5f);
__m128 output = _mm_add_ps(input0, input1);
/* _mm_extract_ps returns int instead of float:
* * https://stackoverflow.com/questions/5526658/intel-sse-why-does-mm-extract-ps-return-int-instead-of-float
* * https://stackoverflow.com/questions/3130169/how-to-convert-a-hex-float-to-a-float-in-c-c-using-mm-extract-ps-sse-gcc-inst
* so we must use instead: _MM_EXTRACT_FLOAT
*/
float f;
_MM_EXTRACT_FLOAT(f, output, 3);
assert(f == 7.0f);
_MM_EXTRACT_FLOAT(f, output, 2);
assert(f == 9.0f);
_MM_EXTRACT_FLOAT(f, output, 1);
assert(f == 11.0f);
_MM_EXTRACT_FLOAT(f, output, 0);
assert(f == 13.0f);
/* And we also have _mm_cvtss_f32 + _mm_shuffle_ps, */
assert(_mm_cvtss_f32(output) == 13.0f);
assert(_mm_cvtss_f32(_mm_shuffle_ps(output, output, 1)) == 11.0f);
assert(_mm_cvtss_f32(_mm_shuffle_ps(output, output, 2)) == 9.0f);
assert(_mm_cvtss_f32(_mm_shuffle_ps(output, output, 3)) == 7.0f);
}
/* Now from memory. */
{
__m128 *input0 = (__m128 *)global_input0;
__m128 *input1 = (__m128 *)global_input1;
_mm_store_ps(global_output, _mm_add_ps(*input0, *input1));
assert(!memcmp(global_output, global_expected, sizeof(global_output)));
}
/* 64-bit add (addpd). */
{
__m128d input0 = _mm_set_pd(1.5, 2.5);
__m128d input1 = _mm_set_pd(5.5, 6.5);
__m128d output = _mm_add_pd(input0, input1);
/* OK, and this is how we get the doubles out:
* with _mm_cvtsd_f64 + _mm_unpackhi_pd
* https://stackoverflow.com/questions/19359372/mm-cvtsd-f64-analogon-for-higher-order-floating-point
*/
assert(_mm_cvtsd_f64(output) == 9.0);
assert(_mm_cvtsd_f64(_mm_unpackhi_pd(output, output)) == 7.0);
}
return 0;
}
GitHub upstream.
paddq.c
#include <assert.h>
#include <inttypes.h>
#include <string.h>
#include <x86intrin.h>
uint32_t global_input0[] __attribute__((aligned(16))) = {1, 2, 3, 4};
uint32_t global_input1[] __attribute__((aligned(16))) = {5, 6, 7, 8};
uint32_t global_output[4] __attribute__((aligned(16)));
uint32_t global_expected[] __attribute__((aligned(16))) = {6, 8, 10, 12};
int main(void) {
/* 32-bit add hello world. */
{
__m128i input0 = _mm_set_epi32(1, 2, 3, 4);
__m128i input1 = _mm_set_epi32(5, 6, 7, 8);
__m128i output = _mm_add_epi32(input0, input1);
/* _mm_extract_epi32 mentioned at:
* https://stackoverflow.com/questions/12495467/how-to-store-the-contents-of-a-m128d-simd-vector-as-doubles-without-accessing/56404421#56404421 */
assert(_mm_extract_epi32(output, 3) == 6);
assert(_mm_extract_epi32(output, 2) == 8);
assert(_mm_extract_epi32(output, 1) == 10);
assert(_mm_extract_epi32(output, 0) == 12);
}
/* Now from memory. */
{
__m128i *input0 = (__m128i *)global_input0;
__m128i *input1 = (__m128i *)global_input1;
_mm_store_si128((__m128i *)global_output, _mm_add_epi32(*input0, *input1));
assert(!memcmp(global_output, global_expected, sizeof(global_output)));
}
/* Now a bunch of other sizes. */
{
__m128i input0 = _mm_set_epi32(0xF1F1F1F1, 0xF2F2F2F2, 0xF3F3F3F3, 0xF4F4F4F4);
__m128i input1 = _mm_set_epi32(0x12121212, 0x13131313, 0x14141414, 0x15151515);
__m128i output;
/* 8-bit integers (paddb) */
output = _mm_add_epi8(input0, input1);
assert(_mm_extract_epi32(output, 3) == 0x03030303);
assert(_mm_extract_epi32(output, 2) == 0x05050505);
assert(_mm_extract_epi32(output, 1) == 0x07070707);
assert(_mm_extract_epi32(output, 0) == 0x09090909);
/* 32-bit integers (paddw) */
output = _mm_add_epi16(input0, input1);
assert(_mm_extract_epi32(output, 3) == 0x04030403);
assert(_mm_extract_epi32(output, 2) == 0x06050605);
assert(_mm_extract_epi32(output, 1) == 0x08070807);
assert(_mm_extract_epi32(output, 0) == 0x0A090A09);
/* 32-bit integers (paddd) */
output = _mm_add_epi32(input0, input1);
assert(_mm_extract_epi32(output, 3) == 0x04040403);
assert(_mm_extract_epi32(output, 2) == 0x06060605);
assert(_mm_extract_epi32(output, 1) == 0x08080807);
assert(_mm_extract_epi32(output, 0) == 0x0A0A0A09);
/* 64-bit integers (paddq) */
output = _mm_add_epi64(input0, input1);
assert(_mm_extract_epi32(output, 3) == 0x04040404);
assert(_mm_extract_epi32(output, 2) == 0x06060605);
assert(_mm_extract_epi32(output, 1) == 0x08080808);
assert(_mm_extract_epi32(output, 0) == 0x0A0A0A09);
}
return 0;
GitHub upstream.
Step 3: go and optimize some code and benchmark it
The final, and most important and hard step, is of course to actually use the intrinsics to make your code fast, and then to benchmark your improvement.
Doing so, will likely require you to learn a bit about the x86 microarchitecture, which I don't know myself. CPU vs IO bound will likely be one of the things that comes up: What do the terms "CPU bound" and "I/O bound" mean?
As mentioned at: https://stackoverflow.com/a/12172046/895245 this will almost inevitably involve reading Agner Fog's documentation, which appear to be better than anything Intel itself has published.
Hopefully however steps 1 and 2 will serve as a basis to at least experiment with functional non-performance aspects and quickly see what instructions are doing.
TODO: produce a minimal interesting example of such optimization here.
Solution 5:
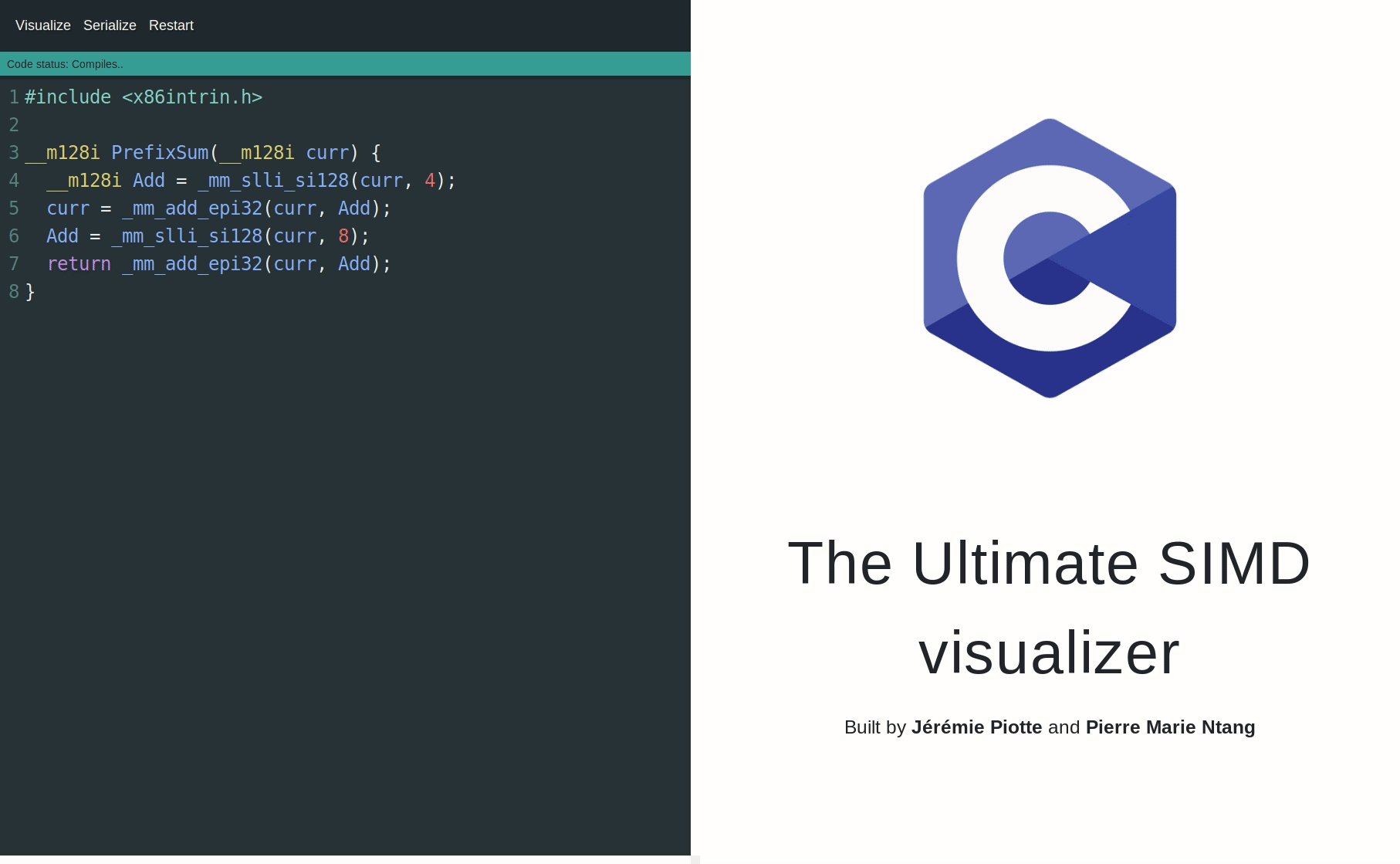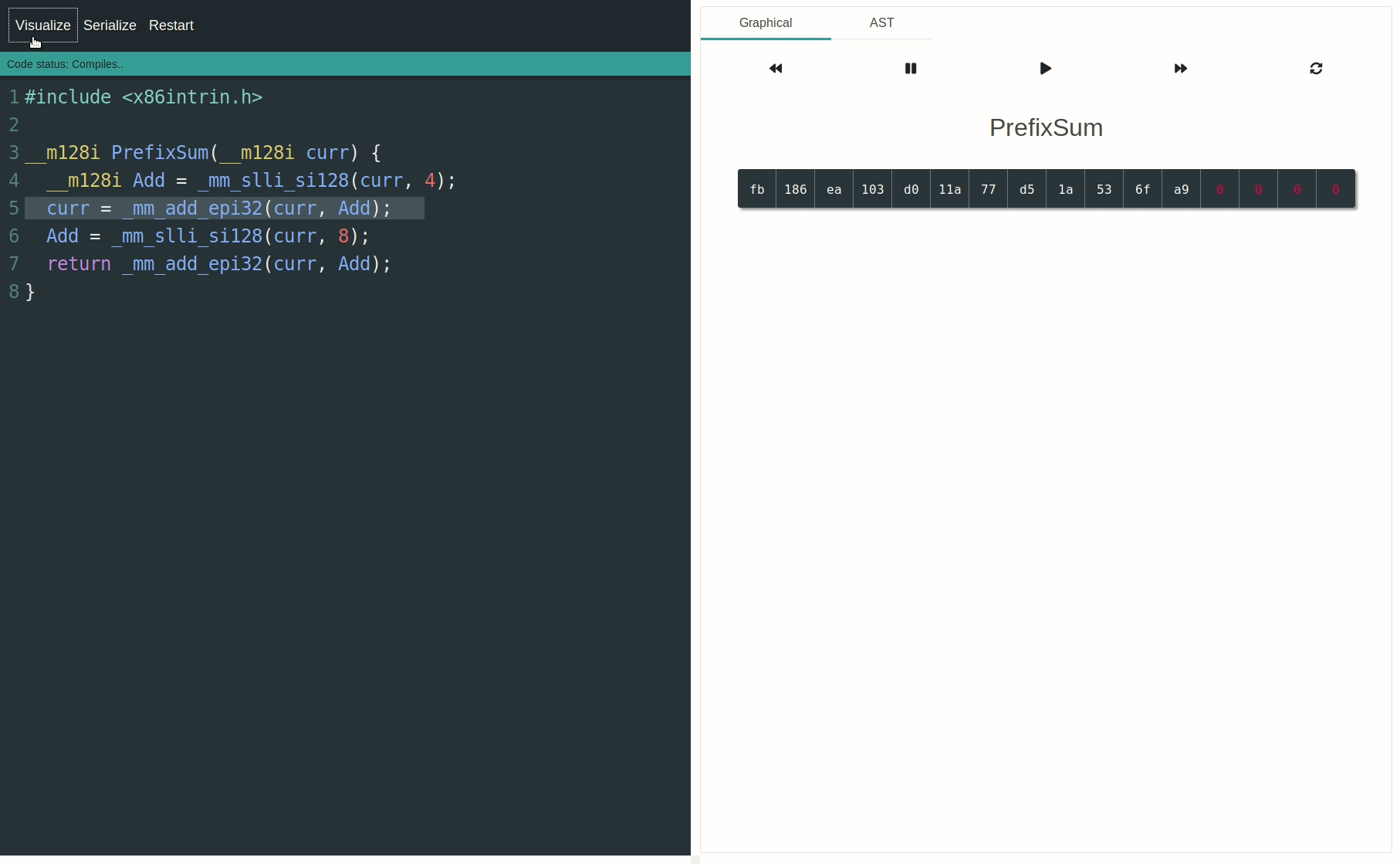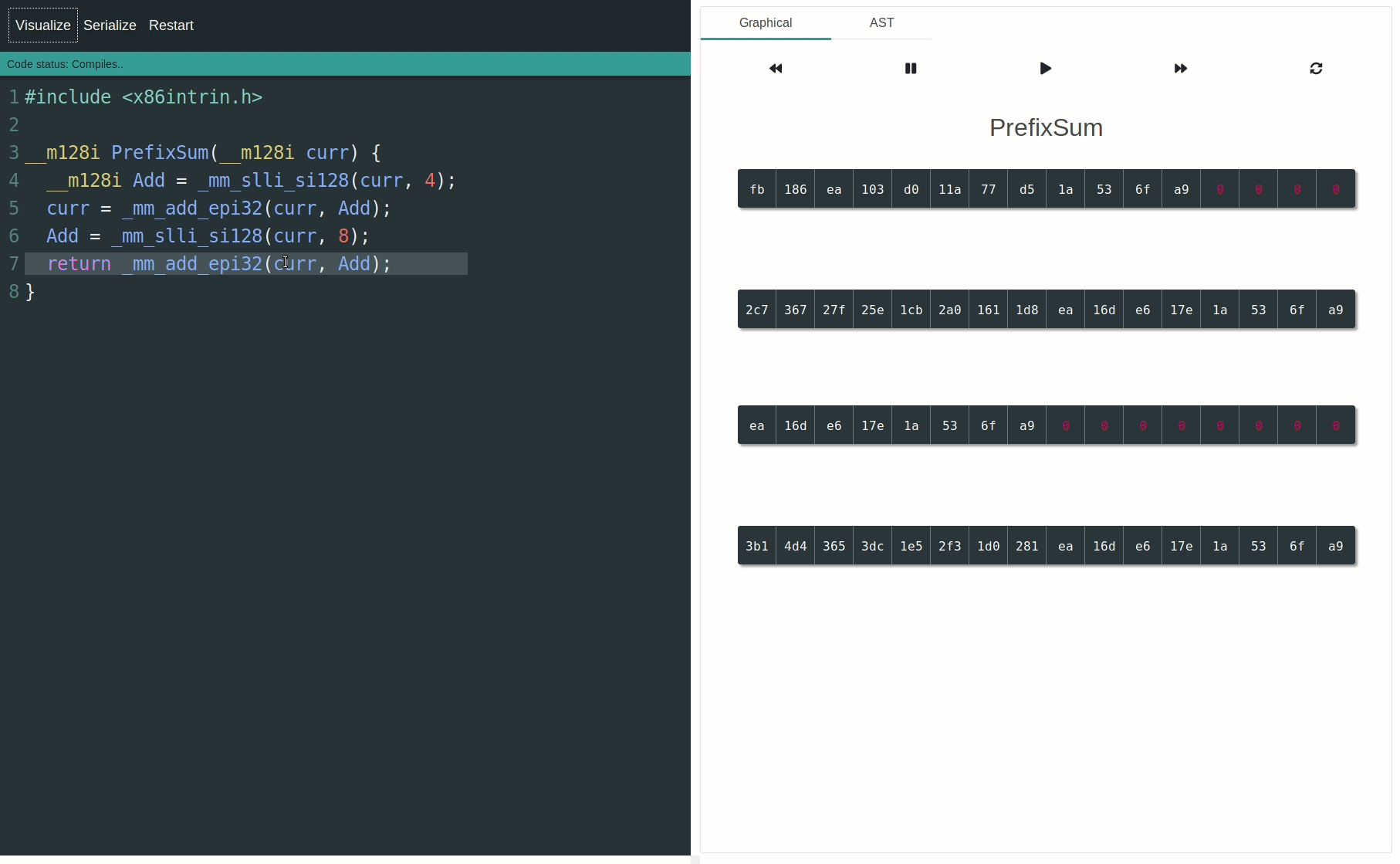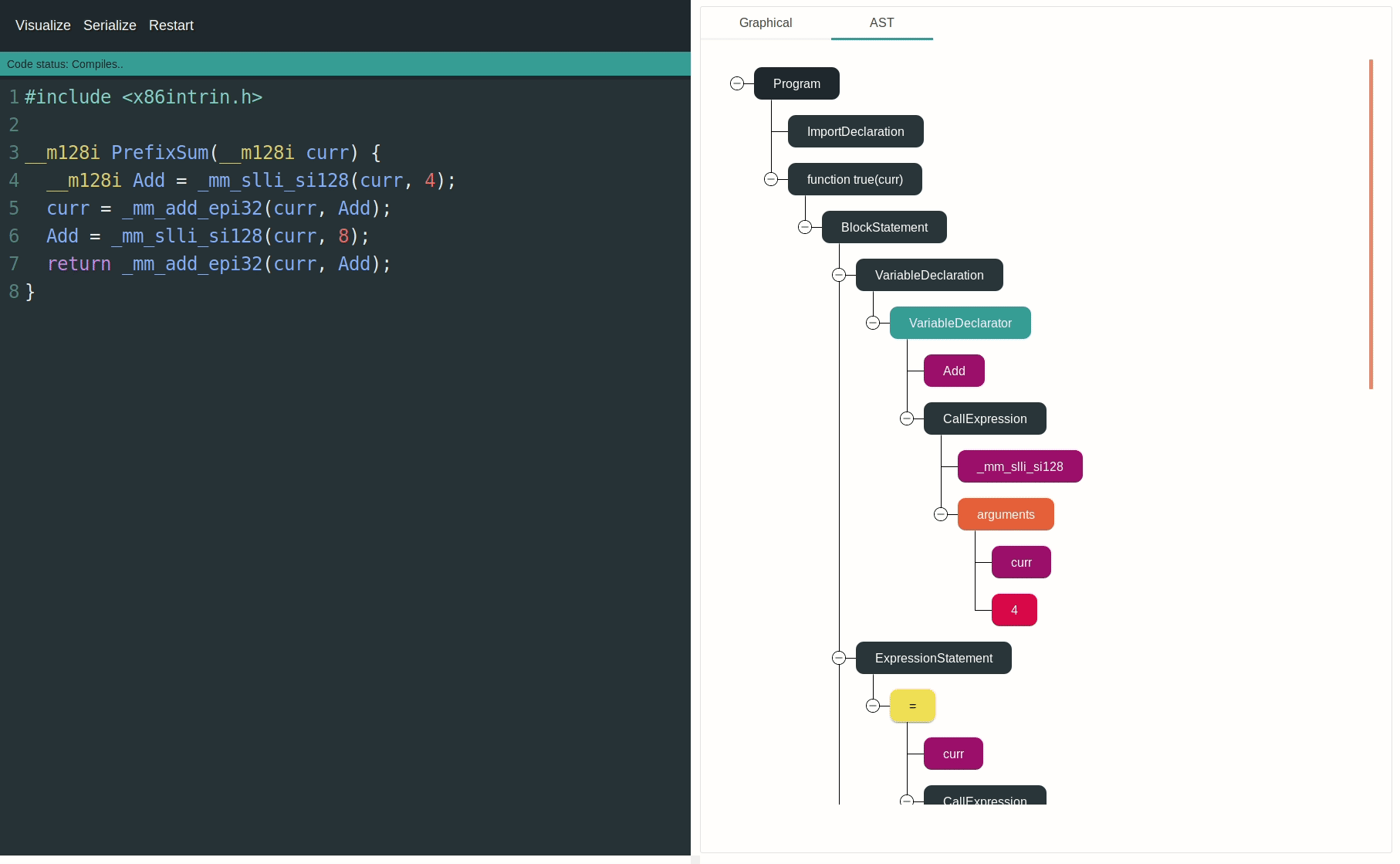
You can use the SIMD-Visualiser to graphically visualize and animate the operations. It'll greatly help understanding how the data lanes are processed