How does this code for standardizing data work?
Solution 1:
This code accepts a data matrix of size M x N, where M is the dimensionality of one data sample from this matrix and N is the total number of samples. Therefore, one column of this matrix is one data sample. Data samples are all stacked horizontally and are columns.
Now, the true purpose of this code is to take all of the columns of your matrix and standardize / normalize the data so that each data sample exhibits zero mean and unit variance. This means that after this transform, if you found the mean value of any column in this matrix, it would be 0 and the variance would be 1. This is a very standard method for normalizing values in statistical analysis, machine learning, and computer vision.
This actually comes from the z-score in statistical analysis. Specifically, the equation for normalization is:
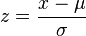
Given a set of data points, we subtract the value in question by the mean of these data points, then divide by the respective standard deviation. How you'd call this code is the following. Given this matrix, which we will call X, there are two ways you can call this code:
- Method #1:
[X, mean_X, std_X] = standardize(X); - Method #2:
[X, mean_X, std_X] = standardize(X, mu, sigma);
The first method automatically infers the mean of each column of X and the standard deviation of each column of X. mean_X and std_X will both return 1 x N vectors that give you the mean and standard deviation of each column in the matrix X. The second method allows you to manually specify a mean (mu) and standard deviation (sigma) for each column of X. This is possibly for use in debugging, but you would specify both mu and sigma as 1 x N vectors in this case. What is returned for mean_X and std_X is identical to mu and sigma.
The code is a bit poorly written IMHO, because you can certainly achieve this vectorized, but the gist of the code is that it finds the mean of every column of the matrix X if we are are using Method #1, duplicates this vector so that it becomes a M x N matrix, then we subtract this matrix with X. This will subtract each column by its respective mean. We also compute the standard deviation of each column before the mean subtraction.
Once we do that, we then normalize our X by dividing each column by its respective standard deviation. BTW, doing std_X(:, i) is superfluous as std_X is already a 1 x N vector. std_X(:, i) means to grab all of the rows at the ith column. If we already have a 1 x N vector, this can simply be replaced with std_X(i) - a bit overkill for my taste.
Method #2 performs the same thing as Method #1, but we provide our own mean and standard deviation for each column of X.
For the sake of documentation, this is how I would have commented the code:
function [X, mean_X, std_X] = standardize(varargin)
switch nargin %// Check how many input variables we have input into the function
case 1 %// If only one variable - this is the input matrix
mean_X = mean(varargin{1}); %// Find mean of each column
std_X = std(varargin{1}); %// Find standard deviation of each column
%// Take each column of X and subtract by its corresponding mean
%// Take mean_X and duplicate M times vertically
X = varargin{1} - repmat(mean_X, [size(varargin{1}, 1) 1]);
%// Next, for each column, normalize by its respective standard deviation
for i = 1:size(X, 2)
X(:, i) = X(:, i) / std(X(:, i));
end
case 3 %// If we provide three inputs
mean_X = varargin{2}; %// Second input is a mean vector
std_X = varargin{3}; %// Third input is a standard deviation vector
%// Apply the code as seen in the first case
X = varargin{1} - repmat(mean_X, [size(varargin{1}, 1) 1]);
for i = 1:size(X, 2)
X(:, i) = X(:, i) / std_X(:, i);
end
end
If I can suggest another way to write this code, I would use the mighty and powerful bsxfun function. This avoids having to do any duplication of elements and we can do this under the hood. I would rewrite this function so that it looks like this:
function [X, mean_X, std_X] = standardize(varargin)
switch nargin
case 1
mean_X = mean(varargin{1}); %// Find mean of each column
std_X = std(varargin{1}); %// Find std. dev. of each column
X = bsxfun(@minus, varargin{1}, mean_X); %// Subtract each column by its respective mean
X = bsxfun(@rdivide, X, std_X); %// Take each column and divide by its respective std dev.
case 3
mean_X = varargin{2};
std_X = varargin{3};
%// Same code as above
X = bsxfun(@minus, varargin{1}, mean_X);
X = bsxfun(@rdivide, X, std_X);
end
I would argue that the new code above is much faster than using for and repmat. In fact, it is known that bsxfun is faster than the former approach - especially for larger matrices.