Is Zookeeper a must for Kafka? [closed]
In Kafka, I would like to use only a single broker, single topic and a single partition having one producer and multiple consumers (each consumer getting its own copy of data from the broker). Given this, I do not want the overhead of using Zookeeper; Can I not just use the broker only? Why is a Zookeeper must?
Yes, Zookeeper is required for running Kafka. From the Kafka Getting Started documentation:
Step 2: Start the server
Kafka uses zookeeper so you need to first start a zookeeper server if you don't already have one. You can use the convenience script packaged with kafka to get a quick-and-dirty single-node zookeeper instance.
As to why, well people long ago discovered that you need to have some way to coordinating tasks, state management, configuration, etc across a distributed system. Some projects have built their own mechanisms (think of the configuration server in a MongoDB sharded cluster, or a Master node in an Elasticsearch cluster). Others have chosen to take advantage of Zookeeper as a general purpose distributed process coordination system. So Kafka, Storm, HBase, SolrCloud to just name a few all use Zookeeper to help manage and coordinate.
Kafka is a distributed system and is built to use Zookeeper. The fact that you are not using any of the distributed features of Kafka does not change how it was built. In any event there should not be much overhead from using Zookeeper. A bigger question is why you would use this particular design pattern -- a single broker implementation of Kafka misses out on all of the reliability features of a multi-broker cluster along with its ability to scale.
As explained by others, Kafka (even in most recent version) will not work without Zookeeper.
Kafka uses Zookeeper for the following:
Electing a controller. The controller is one of the brokers and is responsible for maintaining the leader/follower relationship for all the partitions. When a node shuts down, it is the controller that tells other replicas to become partition leaders to replace the partition leaders on the node that is going away. Zookeeper is used to elect a controller, make sure there is only one and elect a new one it if it crashes.
Cluster membership - which brokers are alive and part of the cluster? this is also managed through ZooKeeper.
Topic configuration - which topics exist, how many partitions each has, where are the replicas, who is the preferred leader, what configuration overrides are set for each topic
(0.9.0) - Quotas - how much data is each client allowed to read and write
(0.9.0) - ACLs - who is allowed to read and write to which topic (old high level consumer) - Which consumer groups exist, who are their members and what is the latest offset each group got from each partition.
[from https://www.quora.com/What-is-the-actual-role-of-ZooKeeper-in-Kafka/answer/Gwen-Shapira]
Regarding your scenario, only one broker instance and one producer with multiple consumer, u can use pusher to create a channel, and push event to that channel that consumer can subscribe to and hand those events. https://pusher.com/
Important update - August 2019:
ZooKeeper dependency will be removed from Apache Kafka. See the high-level discussion in KIP-500: Replace ZooKeeper with a Self-Managed Metadata Quorum.
These efforts will take a few Kafka releases and additional KIPs. Kafka Controllers will take over the tasks of current ZooKeeper tasks. The Controllers will leverage the benefits of the Event Log which is a core concept of Kafka.
Some benefits of the new Kafka architecture are a simpler architecture, ease of operations, and better scalability e.g. allow "unlimited partitions".
Updated on Feb 2021
For the latest version (2.7.0) ZooKeeper is still required for running Kafka, but in the near future ZooKeeper will be replaced with a Self-Managed Metadata Quorum.
See details in the accepted KIP-500.
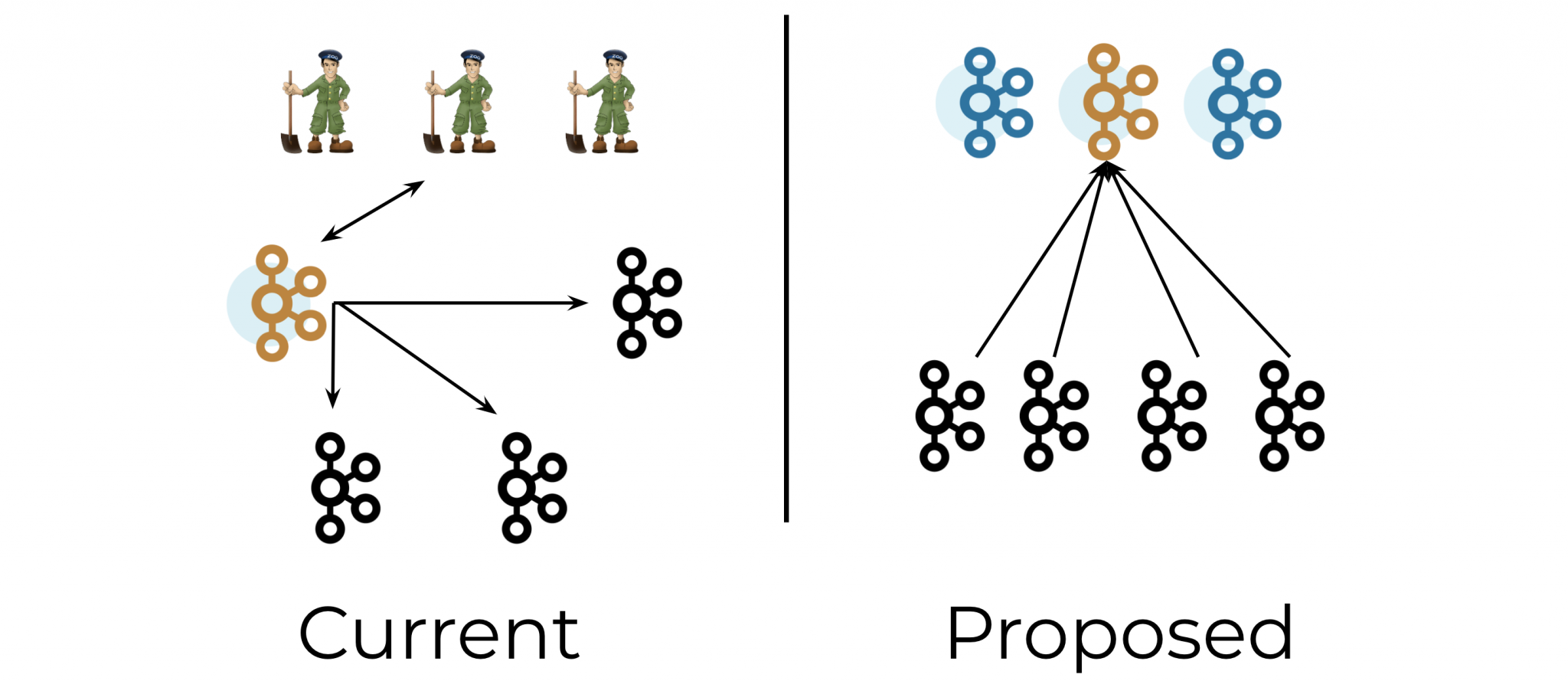
1. Current status
Kafka uses ZooKeeper to store its metadata about partitions and brokers, and to elect a broker to be the Kafka Controller.
Currently, removing this dependency on ZooKeeper is work in progress (through the KIP-500) .
2. Profit of removal
Removing the Apache ZooKeeper dependency provides three distinct benefits:
- First, it simplifies the architecture by consolidating metadata in Kafka itself, rather than splitting it between Kafka and ZooKeeper. This improves stability, simplifies the software, and makes it easier to monitor, administer, and support Kafka.
- Second, it improves control plane performance, enabling clusters to scale to millions of partitions.
- Finally, it allows Kafka to have a single security model for the whole system, rather than having one for Kafka and one for Zookeeper.
3. Roadmap
ZooKeeper removal is expected in 2021 and has some milestones which are represented in the following KIPs:
| KIP | Name | Status | Fix Version/s |
|:-------:|:--------------------------------------------------------:|:----------------:|---------------|
| KIP-455 | Create an Administrative API for Replica Reassignment | Accepted | 2.6.0 |
| KIP-497 | Add inter-broker API to alter ISR | Accepted | 2.7.0 |
| KIP-543 | Expand ConfigCommand's non-ZK functionality | Accepted | 2.6.0 |
| KIP-555 | Deprecate Direct ZK access in Kafka Administrative Tools | Accepted | None |
| KIP-589 | Add API to update Replica state in Controller | Accepted | 2.8.0 |
| KIP-590 | Redirect Zookeeper Mutation Protocols to The Controller | Accepted | 2.8.0 |
| KIP-595 | A Raft Protocol for the Metadata Quorum | Accepted | None |
| KIP-631 | The Quorum-based Kafka Controller | Under discussion | None |
KIP-500 introduced the concept of a bridge release that can coexist with both pre- and post-KIP-500 versions of Kafka. Bridge releases are important because they enable zero-downtime upgrades to the post-ZooKeeper world.
References:
- KIP-500: Replace ZooKeeper with a Self-Managed Metadata Quorum
- Apache Kafka Needs No Keeper: Removing the Apache ZooKeeper Dependency
- Preparing Your Clients and Tools for KIP-500: ZooKeeper Removal from Apache Kafka
Kafka is built to use Zookeeper. There is no escaping from that.
Kafka is a distributed system and uses Zookeeper to track status of kafka cluster nodes. It also keeps track of Kafka topics, partitions etc.
Looking at your question, it seems you do not need Kafka. You can use any application that supports pub-sub such as Redis, Rabbit MQ or hosted solutions such as Pub-nub.