How can I use a cursor.forEach() in MongoDB using Node.js?
I have a huge collection of documents in my DB and I'm wondering how can I run through all the documents and update them, each document with a different value.
Solution 1:
The answer depends on the driver you're using. All MongoDB drivers I know have cursor.forEach() implemented one way or another.
Here are some examples:
node-mongodb-native
collection.find(query).forEach(function(doc) {
// handle
}, function(err) {
// done or error
});
mongojs
db.collection.find(query).forEach(function(err, doc) {
// handle
});
monk
collection.find(query, { stream: true })
.each(function(doc){
// handle doc
})
.error(function(err){
// handle error
})
.success(function(){
// final callback
});
mongoose
collection.find(query).stream()
.on('data', function(doc){
// handle doc
})
.on('error', function(err){
// handle error
})
.on('end', function(){
// final callback
});
Updating documents inside of .forEach callback
The only problem with updating documents inside of .forEach callback is that you have no idea when all documents are updated.
To solve this problem you should use some asynchronous control flow solution. Here are some options:
- async
- promises (when.js, bluebird)
Here is an example of using async, using its queue feature:
var q = async.queue(function (doc, callback) {
// code for your update
collection.update({
_id: doc._id
}, {
$set: {hi: 'there'}
}, {
w: 1
}, callback);
}, Infinity);
var cursor = collection.find(query);
cursor.each(function(err, doc) {
if (err) throw err;
if (doc) q.push(doc); // dispatching doc to async.queue
});
q.drain = function() {
if (cursor.isClosed()) {
console.log('all items have been processed');
db.close();
}
}
Solution 2:
Using the mongodb driver, and modern NodeJS with async/await, a good solution is to use next():
const collection = db.collection('things')
const cursor = collection.find({
bla: 42 // find all things where bla is 42
});
let document;
while ((document = await cursor.next())) {
await collection.findOneAndUpdate({
_id: document._id
}, {
$set: {
blu: 43
}
});
}
This results in only one document at a time being required in memory, as opposed to e.g. the accepted answer, where many documents get sucked into memory, before processing of the documents starts. In cases of "huge collections" (as per the question) this may be important.
If documents are large, this can be improved further by using a projection, so that only those fields of documents that are required are fetched from the database.
Solution 3:
var MongoClient = require('mongodb').MongoClient,
assert = require('assert');
MongoClient.connect('mongodb://localhost:27017/crunchbase', function(err, db) {
assert.equal(err, null);
console.log("Successfully connected to MongoDB.");
var query = {
"category_code": "biotech"
};
db.collection('companies').find(query).toArray(function(err, docs) {
assert.equal(err, null);
assert.notEqual(docs.length, 0);
docs.forEach(function(doc) {
console.log(doc.name + " is a " + doc.category_code + " company.");
});
db.close();
});
});
Notice that the call .toArray is making the application to fetch the entire dataset.
var MongoClient = require('mongodb').MongoClient,
assert = require('assert');
MongoClient.connect('mongodb://localhost:27017/crunchbase', function(err, db) {
assert.equal(err, null);
console.log("Successfully connected to MongoDB.");
var query = {
"category_code": "biotech"
};
var cursor = db.collection('companies').find(query);
function(doc) {
cursor.forEach(
console.log(doc.name + " is a " + doc.category_code + " company.");
},
function(err) {
assert.equal(err, null);
return db.close();
}
);
});
Notice that the cursor returned by the find() is assigned to var cursor. With this approach, instead of fetching all data in memory and consuming data at once, we're streaming the data to our application. find() can create a cursor immediately because it doesn't actually make a request to the database until we try to use some of the documents it will provide. The point of cursor is to describe our query. The 2nd parameter to cursor.forEach shows what to do when the driver gets exhausted or an error occurs.
In the initial version of the above code, it was toArray() which forced the database call. It meant we needed ALL the documents and wanted them to be in an array.
Also, MongoDB returns data in batch format. The image below shows, requests from cursors (from application) to MongoDB
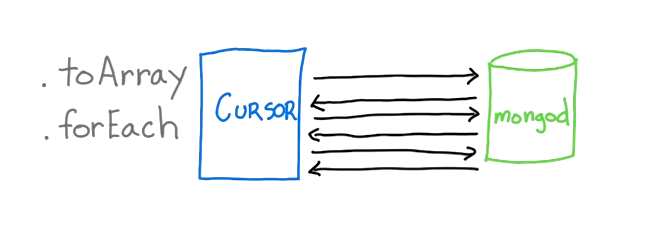
forEach is better than toArray because we can process documents as they come in until we reach the end. Contrast it with toArray - where we wait for ALL the documents to be retrieved and the entire array is built. This means we're not getting any advantage from the fact that the driver and the database system are working together to batch results to your application. Batching is meant to provide efficiency in terms of memory overhead and the execution time. Take advantage of it, if you can in your application.
Solution 4:
None of the previous answers mentions batching the updates. That makes them extremely slow 🐌 - tens or hundreds of times slower than a solution using bulkWrite.
Let's say you want to double the value of a field in each document. Here's how to do that fast 💨 and with fixed memory consumption:
// Double the value of the 'foo' field in all documents
let bulkWrites = [];
const bulkDocumentsSize = 100; // how many documents to write at once
let i = 0;
db.collection.find({ ... }).forEach(doc => {
i++;
// Update the document...
doc.foo = doc.foo * 2;
// Add the update to an array of bulk operations to execute later
bulkWrites.push({
replaceOne: {
filter: { _id: doc._id },
replacement: doc,
},
});
// Update the documents and log progress every `bulkDocumentsSize` documents
if (i % bulkDocumentsSize === 0) {
db.collection.bulkWrite(bulkWrites);
bulkWrites = [];
print(`Updated ${i} documents`);
}
});
// Flush the last <100 bulk writes
db.collection.bulkWrite(bulkWrites);
Solution 5:
And here is an example of using a Mongoose cursor async with promises:
new Promise(function (resolve, reject) {
collection.find(query).cursor()
.on('data', function(doc) {
// ...
})
.on('error', reject)
.on('end', resolve);
})
.then(function () {
// ...
});
Reference:
- Mongoose cursors
- Streams and promises