Why are foreign keys more used in theory than in practice?
When you study relational theory foreign keys are, of course, mandatory. But in practice, in every place I worked, table products and joins are always done by specifying the keys explicitly in the query, instead of relying on foreign keys in the DBMS.
This way, you could of course join two tables by fields that are not meant to be foreign keys, having unexpected results.
Why do you think that is? Shouldn't DBMSs enforce that Joins and Products be made only by foreign keys?
EDIT: Thanks for all the answers. It's clear to me now that the main reason for FKs is reference integrity. But if you design a DB, all relationships in the model (I.E. arrows in the ERD) become Foreign keys, at least in theory, whether or not you define them as such in your DBMS, they're semantically FKs. I can't imagine the need to join tables by fields that aren't FKs. Can someone give an example that makes sense?
PS: I'm aware about the fact that N:M relationships become separate tables and not foreign keys, just omitted it for simplicity's sake.
Solution 1:
The reason foreign key constraints exist is to guarantee that the referenced rows exist.
"The foreign key identifies a column or a set of columns in one table that refers to a column or set of columns in another table. The values in one row of the referencing columns must occur in a single row in the referenced table.
Thus, a row in the referencing table cannot contain values that don't exist in the referenced table (except potentially NULL). This way references can be made to link information together and it is an essential part of database normalization." (Wikipedia)
RE: Your question: "I can't imagine the need to join tables by fields that aren't FKs":
When defining a Foreign Key constraint, the column(s) in the referencing table must be the primary key of the referenced table, or at least a candidate key.
When doing joins, there is no need to join with primary keys or candidate keys.
The following is an example that could make sense:
CREATE TABLE clients (
client_id uniqueidentifier NOT NULL,
client_name nvarchar(250) NOT NULL,
client_country char(2) NOT NULL
);
CREATE TABLE suppliers (
supplier_id uniqueidentifier NOT NULL,
supplier_name nvarchar(250) NOT NULL,
supplier_country char(2) NOT NULL
);
And then query as follows:
SELECT
client_name, supplier_name, client_country
FROM
clients
INNER JOIN
suppliers ON (clients.client_country = suppliers.supplier_country)
ORDER BY
client_country;
Another case where these joins make sense is in databases that offer geospatial features, like SQL Server 2008 or Postgres with PostGIS. You will be able to do queries like these:
SELECT
state, electorate
FROM
electorates
INNER JOIN
postcodes on (postcodes.Location.STIntersects(electorates.Location) = 1);
Source: ConceptDev - SQL Server 2008 Geography: STIntersects, STArea
You can see another similar geospatial example in the accepted answer to the post "Sql 2008 query problem - which LatLong’s exists in a geography polygon?":
SELECT
G.Name, COUNT(CL.Id)
FROM
GeoShapes G
INNER JOIN
CrimeLocations CL ON G.ShapeFile.STIntersects(CL.LatLong) = 1
GROUP BY
G.Name;
These are all valid SQL joins that have nothing to do with foreign keys and candidate keys, and can still be useful in practice.
Solution 2:
Foreign keys have less to do with joins than with keeping database integrity. Proof of that is that you can join tables in any way you want, even in ways that don't necessarily make sense.
Solution 3:
I can't imagine the need to join tables by fields that aren't FKs. Can someone give an example that makes sense?
FOREIGN KEYs can only be used to enforce referential integrity if the relationship between the entities of the ER model is reflected with an equijoin between two relations in the relational model.
This is not always true.
Here's an example from the article in my blog I wrote some time ago:
- What is entity-relationship model?
This model describes goods and price ranges:
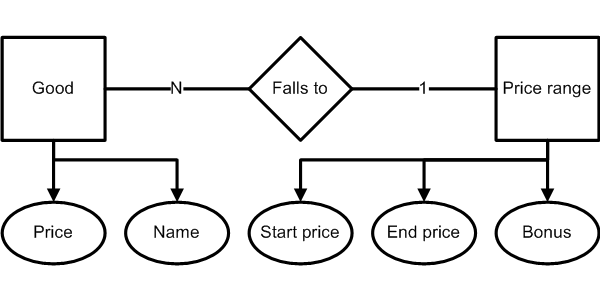
And here's the relational implementation of the model:
CREATE TABLE Goods (ID, Name, Price)
CREATE TABLE PriceRange (Price, Bonus)
As you can see, the PriceRange table has only one price-related attribute, Price, but the model has two attributes: StartPrice and EndPrice.
This is because relational model allows transforming the sets and the entity PriceRange can be easily reconstructed using SQL operations.
Goods
ID Name Price
1 Wormy apple 0.09
2 Bangkok durian 9.99
3 Densuke watermelon 999.99
4 White truffle 99999.99
PriceRange
Price Bonus
0.01 1%
1.00 3%
100.00 10%
10000.00 30%
We store only the lower bound of each range. Upper bound can easily be inferred.
Here's the query to find the bonus for each good:
SELECT *
FROM Goods
JOIN PriceRange
ON PriceRange.Price =
(
SELECT MAX(Price)
FROM PriceRange
WHERE PriceRange.Price <= Goods.Price
)
We see that these relational model implements the ER model fairly well, but no foreign key can be declared between these relations, since the operation used to bind them is not an equijoin.
Solution 4:
No, the enforcement is unnecessary; it would disallow some useful functionality, such as the possible overloading of columns. While this sort of use isn't ideal, it IS useful in some real-world situations.
The appropriate use for Foreign key constraints is just as that; a constraint upon values added to a given column that assures that their referenced rows exist.
It should be noted that a significant lack of foreign key constraints on a given schema is a bad "smell", and can indicate some serious design problems.
Solution 5:
You can join on any expression. Whether you define foreign keys in your database or not is immaterial. Foreign keys constrain INSERT/UPDATE/DELETE, not SELECT.
So why do lots of projects skip defining foreign keys? There are several reasons:
The data model is designed poorly and requires broken references (examples: polymorphic associations, EAV).
The coders may have heard that "foreign keys are slow" so they drop them. In fact, the extra work you have to do to ensure data consistency when you can't rely on foreign keys makes your app much less efficient. Premature optimization without actually measuring the benefit is a common problem.
Constraints get in the way of some data cleanup tasks. Sometimes you need to break references temporarily as you refactor data. Many RDBMS allow constraints to be disabled, but sometimes the programmers decide it's easier to leave them disabled. If there's a frequent need for disabling the constraints, this probably indicates a seriously broken database design.